Comme il est bien connu dans l’analyse mathématique, la dérivée et l’intégrale d’une fonction sont les principales métriques dans l’analyse de cette fonction. Historiquement parlant, la découverte de la dérivée et des mathématiques analytiques fut une révolution qui changea le cours des sciences à jamais. Cette découverte a été faite par l’un des plus grands savants de l’histoire, à savoir Isaac Newton. Ce qui la fait connaître avec les 3 lois de la physique mécanique.
Le principe de la dérivée est assez simple, c’est la quantité de changement dans une fonction autour d’une valeur donnée. En géométrie, ça représente la pente de la fonction dans un point x. Les méthodes mathématiques pour calculer cette dérivée sont bien connues depuis des siècles déjà. Mais ils sont, disons moins efficacement implémentés sur ordinateur. La méthode décrite sur la vidéo de la chaine YouTube Computerphile est bluffante. Elle se base sur une supposition de l’existence d’un nombre irréel, comme pour les nombres imaginaires. Et à partir de là, le calcul de la dérivée devient beaucoup plus simple.
Dans l’informatique domestique, ou la micro-informatique (PC). Deux noms de processeurs très connus partagent le marché depuis très longtemps, et avec souvent une concurrence féroce. En l’occurrence les processeurs d’Intel, et les processeurs d’AMD. Mais il y a une décennie de cela, un nouveau processeur a été développé, et qui semble prometteur pour prendre une part dans ce marché concurrentiel très prisé. C’est un processeur nommé RISC-V, développé par un groupe de chercheurs de l’université de Berkeley, pour remédier à un gros désavantage des processeurs actuels, qui est les droits d’utilisation. RISC-V propose une architecture ouverte, plus précisément appelée open ISA. Ce qui permet à n’importe quelle entreprise dans le monde de fabriquer son propre processeur et d’être compatible avec le logiciel des processeurs RISC-V. Ce qui n’est pas le cas pour les autres processeurs. Des droits, ou ce qu’on appelle parfois Royalties, doivent être payés par quiconque voulant utiliser la même architecture qu’eux. Avec des prix qui sont souvent très onéreux, ce qui limite énormément la concurrence dans ce marché.
Jusqu’à maintenant, le processeur RISC-V a gagné beaucoup de popularité dans les processeurs dits processeurs de Systèmes Embarqués. C’est le marché des processeurs pour les appareils électroniques ou les machines qui ne sont pas des PC. Mais comme présenté sur la vidéo en haut, de la chaîne YouTube Explaining Computers. Beaucoup de personnes pensent que le processeur possède beaucoup de potentiel pour concurrencer avec les processeurs du marché des PC. Notamment grâce à son architecture simple, modulaire et extensible. Qui semble plus maîtrisée que l’architecture x86 des processeurs AMD et Intel, avec son important héritage de plus de 40 ans, lui infligeant (pour des raisons de rétrocompatibilité) beaucoup de technologies et d’instructions devenues de nos jours obsolètes.
Je viens de tomber par hasard sur des vidéos sur YouTube d’un simulateur qui permet de créer et de simuler l’interaction dans l’espace des planètes, des systèmes solaires, des étoiles, et des objets célestes. Le nom de l’application en question est Universe Sandbox. Le terme sandbox(bac-à-sable en français) signifie généralement des simulateurs ou des jeux vidéo dans lesquels l’utilisateur ou le joueur n’a pas précisément un chemin prédéfini à suivre, ou un but final à atteindre. Mais plutôt, il a la liberté de créer ce qu’il veut, de faire réellement ce que son imagination lui dicte. L’exemple le plus connu d’un jeu sandbox est sans doute le jeu Minecraft, dans lequel le joueur a la liberté de créer ce qu’il veut avec les outils et les ressources qu’il dispose à sa disposition.
Démonstration de Universe Sandbox
C’est la même chose ici pour ce simulateur Universe Sandbox. L’utilisateur a la possibilité de créer des planètes, des étoiles, des systèmes solaires, des astéroïdes…etc., et il peut simuler l’interaction entre ces objets. Cependant, l’exercice le plus connu dans ce simulateur est de faire des changements dans notre système solaire, et voir comment ça va se répercuter sur l’environnement de la terre. Il est par exemple possible de faire projeter un astéroïde sur la terre et voir la simulation de l’impact de l’astéroïde. Ou de faire changer, par exemple, la taille du soleil et voir les répercussions sur l’atmosphère de la terre. Ou bien faire approcher un trou noir, une étoile pulsar, ou une autre toile avec une masse importante pour observer les implications de sa gravité sur le système solaire… etc. Une démonstration sur les possibilités du simulateur est présentée sur la vidéo en haut.
Lorsqu’une entreprise ou une société possède un parc ou un réseau informatique conséquent, très rapidement un besoin se fera sentir pour subdiviser ce grand réseau en petits réseaux séparés indépendants offrant une infrastructure plus gérable et plus organisée. Le besoin le plus évidant est bien sûr l’organisation et la simplification de gestion. Mais en plus de ça, ça va aussi aider à hausser le degré de confidentialité des données et de la sécurité du réseau. Ça va aussi améliorer les performances du réseau avec une réduction dans la collision des paquets. Faciliter le déploiement logiciel et l’intégration de services de stockage, impression, et backup. Et encore d’autres avantages.
Subnet vs LANs
Deux types de segmentation de réseaux locaux existes. La subdivision en Subnet. Une technique qui se base principalement sur la configuration des adresse IP des machines du sous-réseaux. De l’utilisation d’un Switch basique ou un hub pour chaque sous-réseau. Et l’utilisation des routeurs pour la communication inter-réseau. Le deuxième cas de figure sont les VLAN, ou les sous-réseaux virtuels. Dans ce cas, la configuration des adresses IP des machines est minimale, mais ça exige un Switch évolué. Le Switch est le principal responsable de la subdivision des sous-réseaux, et il doit être configuré en conséquence.
Le langage C est le langage de programmation favori de beaucoup d’universités pour apprendre la programmation aux étudiants. La raison est que ce langage est un langage bas niveau, indiquant que c’est un langage qui ressemble beaucoup au langage machine d’un ordinateur. Ce qui va permettre de familiariser les étudiants à la manière dont la machine à l’intérieur fonctionne réellement. Le 2e point fort du langage C, c’est la popularité de sa syntaxe dans d’autres langages développés après lui, comme par exemple le C++, le C#, le le PHP…etc. Son 3e point fort et sa popularité industrielle, car dans beaucoup de domaines le langage C malgré son ancienneté reste le langage dominant, ça inclut entre autres la programmation système, la programmation des systèmes embarqués ,les jeux vidéo…etc.
Cours Langage C
Ainsi, la vidéo suivante est une vidéo d’un excellent cours sur ce langage C. Cette vidéo est présentée dans le site web PortfolioCourses et dans la chaîne YouTube dédiée.
Il existe quelques domaines scientifiques qui sont plus inaccessibles que d’autres. Et on pourrait facilement mentionner l’électronique et la mécanique quantique. Pourquoi, comme titre d’exemple, ces 2 disciplines sont plus difficiles à apprendre que d’autres ? La raison est qu’ils sont impalpables, on ne peut pas directement les voir, on ne peut pas directement les toucher. Dans notre esprit, ça reste juste des modèles imaginatifs qu’on ne peut guère réellement apercevoir par nos 5 sens.
Circuit mécanique pour faire analogie aux circuits électrique
C’est pour cette raison que pour faire comprendre l’électronique aux étudiants, les enseignants font l’analogie à l’eau qui circule dans un circuit de tuyauterie. Ainsi, l’électricité qui traverse un fil électrique peut être représentée par l’eau qui circule dans un tuyau. Et à vrai dire, il y a beaucoup de similitudes entre l’électricité et l’eau dans ce cas précis. Par exemple, la batterie peut être représentée par une citerne d’eau qui alimente la tuyauterie d’une maison par exemple. Le voltage est représenté par la hauteur de l’eau à l’intérieur de la citerne, ou aussi l’aperçu comme la pression de l’eau. L’ampérage c’est le débit en litre par seconde d’eau dans un tuyau. La résistance c’est le diamètre du tuyau, plus un tuyau est serré, plus la résistance est élevée. Un condensateur est représenté par une membrane ou diaphragme élastique qui bloque le tuyau. L’inducteur comme un moulin à eau avec une certaine masse. La diode comme une valve à sens unique. Le transistor, plus ou moins comme un robinet. Les jointures de plusieurs fils électriques comme les T de tuyaux…etc. Plusieurs formules pour les phénomènes physiques sont similaires, mais parfois ça ne colle pas, notamment lorsque cela implique le courant électrique alternatif.
Étonnamment, l’utilisation des engrenages mécaniques est aussi un très bon moyen pour simuler le fonctionnement des circuits électriques. La vidéo m’a vraiment impressionné par la capacité de ces mécanismes mécaniques à pouvoir reproduire le fonctionnement de circuits électroniques bien connus. Comme le Pont diodes, l’Oscillateur, les filtres Passe-Haut et Passe-bas,la Flip-flop, ou la porte Xor. Que d’ailleurs, je ne pense pas faisable avec des tuyaux d’eau. La vidéo et celle de Steve Mould. C’est sur sa chaîne YouTube, d’ailleurs c’est une excellente chaîne dédiée pour faire apprendre la science et la technologie.
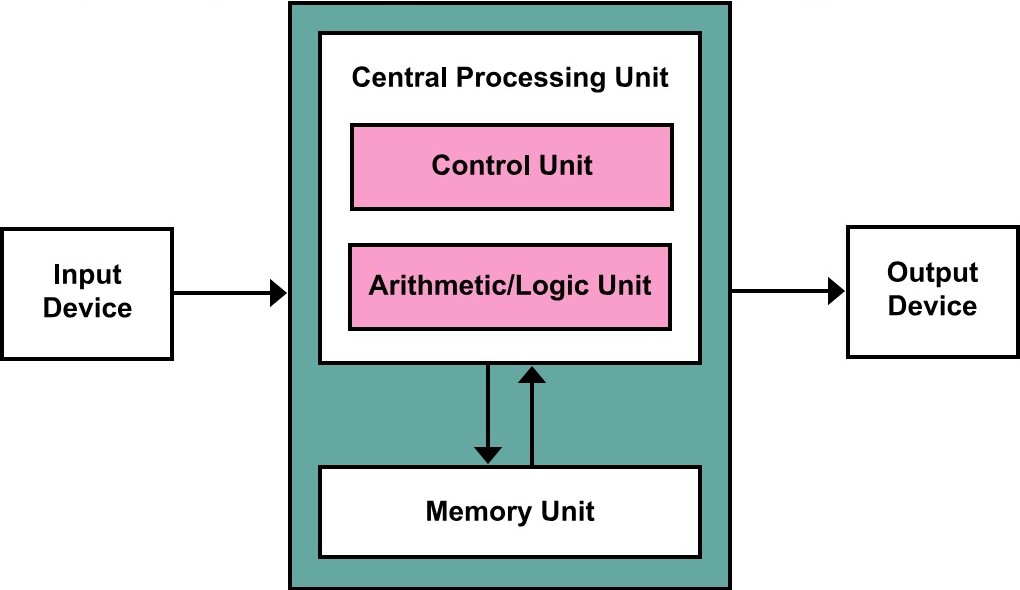
Voici une vidéo qui fait un excellent travail pédagogique pour faire comprendre plus ou moins en détail comment une architecture d’ordinateur fonctionne à l’intérieur. Plus précisément, et en suivant l’architecture de von Neumann (Illustré sur l’image en bas), la vidéo se focalise principalement sur l’interconnexion entre les 3 composantes des architectures de von Neumann, qui sont le processeur, la mémoire, et les unités d’entrée/sortie. Cela dit, il est important d’avoir une vue globale sur l’architecture et comment elle fonctionne d’une manière générale et théorique, il est aussi très important de comprendre le détail. Ainsi, la vidéo suivante démontre en détail comment le processeur arrive à communiquer avec la mémoire et les unités d’entrée/sortie.
L’achitecture de von Neumann
Néanmoins, un point très important à prendre en considération. L’explication donnée dans cette vidéo concerne plus particulièrement les architectures anciennes, des architectures pratiquement des années 80. De nos jours, les ordinateurs et les PC ont totalement évolué et changé de manière de communiquer. C’est devenu beaucoup plus complexe pour que ça soit enseigné à des étudiants universitaires en première ou 2e année. La vidéo en question est celle de la chaîne YouTube de Ron Mattino, c’est une très bonne chaîne bien connue pour faire de la vulgarisation en informatique et en électronique.
Il y a 2 mois de cela s’est déroulée au Colorado aux États-Unis, la plus importante conférence en recherche scientifique concernant les nouvelles technologies utilisées dans la 3D et la synthèse d’image. La conférence en question s’appelle siggraph, et vous pouvez visiter le site officiel pour voir l’état de l’art sur les différentes technologies présentées dans la conférence. Mais pour notre part, comme illustré sur la vidéo en bas, on va juste s’intéresser à l’utilisation de l’IA dans les domaines qui peuvent aboutir dans le domaine du jeu vidéo. La vidéo question et celle de la chaîne Youtube Two Minute Papers, une chaîne très connue et répandue pour ses présentations de la recherche académique dans le domaine de l’intelligence artificielle.
L’intelligence artificielle dans synthèse 3D
L’apport de l’IA dans le domaine du jeu vidéo dans le futur sera sans doute non négligeable. Par exemple, sur la vidéo on peut voir l’évolution des techniques du texte vers image, qui permettent en utilisant l’IA, de générer des images de haute qualité en arrivant même à contrôler les personnages dans l’image en question, ainsi que les postures et les formes générales des personnages et des objets se trouvant dans l’image. On peut apercevoir aussi la génération automatique des vidéos par l’IA, qui commencent à devenir de plus en plus qualitatives et plus réalistes. Ou ce qui m’a vraiment impressionné, la génération d’objets en 3D à partir d’un texte, ce qui va grandement simplifier le travail des artistes dans le domaine vidéoludique. Sans oublier l’efficacité de l’IA à pouvoir faire la simulation physique réaliste avec peu de ressources, car pour faire la simulation réaliste en utilisant les méthodes classiques, la machine devrait être superbement puissante. Et le dernier point impressionnant dans cette conférence, c’est l’amélioration de la technique du Ray tracing, cette technique récemment intégrée dans les cartes graphiques pour plus de réalisme dans le rendu 3D. Les nouvelles techniques de simulation considèrent la lumière non plus comme un faisceau lumineux, mais comme des ondes électromagnétiques, ce qui est de plus en plus fidèle à la réalité physique du phénomène.
On a déjà au préalable évoqué dans un blogprécédant un algorithme de recherche très connu qu’est celui de Dijkstra. On avait évoqué l’importance des algorithmes de recherche, ça permet principalement pour les logiciels de navigation comme titre d’exemple, de trouver d’une façon méthodique le plus court chemin à partir de votre position actuelle dans une carte vers une destination donnée. L’algorithme évoqué dans la vidéo en bas de la chaîne YouTube Computerphileest tout aussi important, C’est l’algorithme A* et représente une réelle amélioration de l’algorithme de Dijkstra.
L’agorithme A*
Lorsque nous avons décrit précédemment l’algorithme de Dijkstra, ça nous a sauté aux yeux combien l’algorithme était si intuitif. En prenant un papier et un crayon, et avec un peu de chance il est possible redécouvrir l’algorithme par soi-même. L’hypothèse de départ est que vous avez une carte de plusieurs villes interconnectées par des routes avec des distances différentes, le but est de trouver le plus court chemin d’une ville de départ vers une ville d’arrivée. Intuitivement, on va commencer par la ville de départ avec une distance de 0, et explorer les voisins directs de cette ville tout en avantageant la ville la plus proche. Algorithmiquement, ça va être une file qui contient la liste ordonnée des villes intermédiaires avec leurs distances à la ville de départ. Ce même processus l’exploration va se répéter pour la tête de file, donc la ville la plus proche. Et continuez au fur et à mesure avec les autres villes jusqu’à y arriver à la ville de destination. Bien sûr dès qu’on termine l’exploration d’une ville en doit la supprimer de la liste, puisque c’était au préalable la ville la plus proche et c’est impossible de trouver dans la liste des villes suivantes un chemin plus cours. Il faut aussi entre-temps mettre à jour les distances des villes anciennement explorées si un nouveau chemin plus court est découvert.
Comparaison de Dijkstra et A*
L’algorithme A* représente une extension de l’algorithme de Dijkstra. Il va utiliser ce qu’on appelle en mathématiques une heuristiquepour améliorer l’algorithme de Dijkstra. L’heuristique est une amélioration intelligente de l’algorithme de Dijkstra en le poussant plus rapidement vers la destination, et en lui évitant de faire l’exploration de la totalité des courts chemins. Cette amélioration est aussi si intuitive que l’algorithme de Dijkstra lui-même. Il a suffi de modifier l’algorithme non plus d’ordonner la liste des villes par le plus court chemin, mais par l’addition du plus court chemin avec la distance directe (ou à vol d’oiseau) de la ville vers la destination. Ainsi les villes les plus loin de la destination vont être pénalisées et les villes les plus proches vont être avantagées. On peut voir sur la vidéo en haut de la comparaison entre l’algorithme Dijkstra et l’algorithme A*, et comment l’algorithme de Dijkstra fait l’exploration en largeur et le A* étend son exploration vers la destination. Contrairement à l’algorithme de Dijkstra, l’algorithme A* ne garantit pas le plus court chemin.
Le path-fider du jeu StarCraft
L’algorithme A* étoile n’est pas aussi précis que l’algorithme de Dijkstra, mais il a l’avantage d’être beaucoup plus rapide. Ce qui le rend un candidat idéal pour les applications temps réel, où le temps de réponse doit être rapide ou borné. C’est particulièrement vrai pour les jeux vidéo avec une vue de haut, où il faut cliquer sur la souris et laisser le caractère trouver son propre chemin sur le terrain. Ça concerne principalement les jeux de stratégie RTSet les jeux de rôle RPGisométrique. L’algorithme assurant le chemin du caractère vers sa destination est généralement appelé Path-Finder. Vous pouvez voir par exemple sur l’image en haut, l’algorithme A* utilisé comme Path-Finder dans le très célèbre jeu de stratégie StarCraft. D’autres algorithmes plus modernes et plus efficaces sont utilisés comme Path-Finder dans les jeux modernes. L’algorithme A* est aussi utilisé en intelligence artificielle pour la résolution des labyrinthes, du rubik’s cube, ou le puzzle du Taquin, et beaucoup bien d’autres.
Non dans un but de l’embellir, le langage C++ est un des langages proéminent dans le paysage de l’informatique moderne. C’est un langage souvent enseigné dans les instituts et universités, et souvent prédominants dans certains secteurs industriels, comme les systèmes embarqués, les jeux vidéo, la robotique, l’automobile, l’aéronautique, et beaucoup d’autres.
La vidéo en bas est l’interview du créateur du langage C++, c’est le danois Bjarne Stroustrup, par le célèbre académicien Lex Fridman sur sa chaîne Youtube de Podcast. Il a commencé la conception du langage dans le début des années 80 dans les laboratoires Bell Labs aux États-Unis. Il explique sur la vidéo comment il s’est inspiré du langage orienté objet Simula, et comment l’introduction de la Programmation Orientée Objet a fait un bond historique énorme sur la courbe d’évolution des langages de programmation.
Interview de Bjarne Stroustrup
La principale innovation derrière le langage C++ et la programmation orientée objet est de donner au programmeur la faculté et la flexibilité de créer ses propres types (appelés Classes), et la personnification de l’interaction entre leurs éléments (appelés Objets), ainsi permettre aux programmeurs de créer leurs propres opérations (appelés Méthodes). Ce qui était au préalable fixe ou limité dans les précédents langages de programmation. Le C++ apporte aussi l’Héritage et le Polymorphisme. Le premier permet de réduire la définition et inter-lier les différents types créés. Et le 2e permet de choisir automatiquement l’opération adéquate et spécifique au type impliqué dans l’opération.
La partie à mon sens, la plus intéressante de l’interview, est lorsque Bjarne Stroustrup explique sa philosophie et sa vision directrice lors de la création du langage, c’est ce qui appelle zero-overhead, c’est mis en-avant sur la vidéo en bas. Son critère était qu’un mécanisme ou une abstraction pour qu’elle soit intégrée au langage, elle ne doit ajouter aucune ou zéro surcharge aux performances du programme. Comme par exemple pour les Classes, Il est toujours possible de recréer un concept similaire dans le langage C, mais d’un point de vue de programmation c’est plus facile de le faire en C++, et c’est surtout équivalent du point de vue de performance. C’est de même pour les Templates ou la programmation Générique. Bjarne Stroustrup a aussi fait l’explication d’un nouveau mécanisme appelé Concept, qui pour faire simple, permet aux programmeurs d’imposer des contraintes sur les opérations possibles sur les nouveaux types créés. Comme par exemple, on ne peut pas faire des opérations arithmétiques sur un type de chaînes de caractères.